Hello Everyone! Good to see you all after a long time!!.
In this tutorial we will see some good points to keep in mind while doing an API design.
The API design practice seems challenging always. Even when there are so many options out there—tools to use, standards to apply, styles to follow—there is one basic question that needs to be answered and needs to be clear in the developer’s mind before any kind of design and development can begin.
A good API
As we all know, the concepts of “good” and “bad” are very subjective (one could probably read a couple of books discussing this on their own), and therefore, opinions vary from one person to another. Any way years of experience dealing with API design will let us define some best practices that to keep in mind.
There are some common practices that we need to consider while developing an API. Such as;
• Developer-friendly: The developers working with our API should not suffer when dealing with our system.
• Extensibility: Our system should be able to handle the addition of new features without breaking our clients.
• Proper error handling: Because things will go wrong and we need to be prepared.
• Security: A key aspect of any global system.
• Scalability: The ability to scale up and down is something any good API should have to properly provide its services.
• Up-to-date documentation: Good documentation is key to our API being picked up by new developers.
• Provides multiple SDK/libraries: The more work we simplify for developers, the more they’ll like our system
Now we will go over these points one by one and show how they affect the API and how following the REST style help.
Developer-Friendly
An API is an application programming interface, with the keyword being interface. When thinking about designing an API that will be used by developers other than ourselves, there is a key aspect that needs to be taken into consideration: the Developer eXperience (or DX).
Even when the API will be used by another system, the integration into that system is first done by one or more developers—human beings that bring the human factor into that integration. This means we’ll want the API to be as easy to use as possible, which makes for a great DX, and which should translate into more developers and client applications using the API.
It is important to consider the DX as one of the major aspects of an API. Now let’s discuss some pointers for a good DX.
Communication’s Protocol
This is one of the most basic aspects of the interface. When choosing a communication protocol, it’s always a good idea to go with one that is familiar to the developers using the API. There are several standards that already have libraries and modules available in many programming languages (e.g., HTTP, FTP, SSH, etc.). A custom-made protocol isn’t always a good idea because we’ll lose that instant portability in so many existing technologies. In the end, it’s up to the API designer to evaluate the best solution based on the context in which he’s working. Any it is most common that most of the systems are using HTTP as the communication protocol and modern programming languages support it and it’s the basis for the entire Internet.
Easy-to-Remember Access Points
The points of contact between all client apps and the API are called endpoints. The API needs to provide them to allow clients to access its functionalities. This can be done through whatever communications protocol is chosen. These access points should have unique names to help the developer understand their purpose just by reading them.
The following is a good example of a badly named access point (meant to list the courses in a learning platform): GET /courses/action1
This example uses the HTTP protocol to specify the access point, and even though the entity used (courses) is being referenced, the action name is not clear; action1 could mean anything, or even worse, the meaning could change in the future, but the name would still be suitable, so any existing client would undoubtedly break.
A better example—one that follows REST and the standards: GET /courses
This should present the developer with more than enough information to understand that a GET request into the root of a resource (/courses) will always yield a list of items of this type; then the developer can replicate this pattern into other resources, as long as the interface is kept uniform across all other endpoints.
Uniform Interface
Easy-to-remember access points are important, but so is being consistent when defining them. Again, we have to go back to the human factor when consuming an API: we’re a human too. So making the lives of the developers using our APIs easier is a must if we want anyone to use it, we can’t forget about the DX. That means we need to be consistent when defining endpoints’ names, request formats, and response formats.
An example of bad design practice in an API is to name the endpoints based on the actions are taken instead of the resources handled; for example:
/getAllBooks
/submitNewBook
/updateAuthor
/getBooksAuthors
/getNumberOfBooksOnStock
To solve this problem and generate an easy-to-use and uniform interface across the entire API, we can apply the REST style to the endpoints as follows,

Transport Language
Another aspect of the interface to consider is the transport language used. For many years, the de facto standard was XML; it provided a technology-agnostic way of expressing data that could easily be sent between clients and servers. Nowadays, there is a new standard gaining popularity over XML— it’s JSON.
Extensibility
Another aspect of good API is never fully finished. This might be a bold claim, but it’s one that comes from the experience of the community.
Let’s look at
• Google APIs: 5 billion calls a day; launched in 2005
• Facebook APIs: 5 billion calls a day; launched in 2007
• Twitter APIs: 13 billion calls a day; launched in 2006
https://www.slideshare.net/3scale/apis-for-biz-dev-20-which-business-model-15473323
These examples show that even when a great team is behind the API, the APIs will keep growing and changing because the client apps developers find new ways to use it, the business model of the API owner changes over time, or simply because features are added and removed. When any of this happens, the API may need to be extended or changed, and new access points added or old ones changed. If the original design is right, then going from v1 to v2 should be no problem, but if it’s not, then that migration could spell disaster for everyone.
Proper Error Handling
Error handling on an API is incredibly important because if it is done right, it can help the client app understand how to handle errors; and on the human side (the DX), it can help developers understand what it is they’re doing wrong and how to fix it. There are two very distinct moments during the life cycle of an API client that we need to consider error handling:
• Phase 1: The development of the client
• Phase 2: The client is implemented and being used by end-users.
Phase 1: Development of the Client
During the first phase, developers implement the required code to consume the API. It is very likely that a developer will have errors on the requests (things like missing parameters, wrong endpoint names, etc.) during this stage. Those errors need to be handled properly, which means returning enough information to let developers know what they did wrong and how they can fix it.
A common problem with some systems is that their creators ignore this stage, and when there is a problem with the request, the API crashes, and the returned information is just an error message with the stack trace and the status code 500
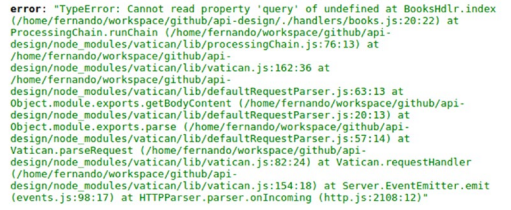
The above picture’s response shows what happens when we forget to add error handling in the client development stage. The stack trace returned might give the developer some sort of clue (at best) as to what exactly went wrong, but it also shows a lot of unnecessary information, so it ends up being confusing.
On the other hand, let’s take a look at a proper error response for the same error in the below Figure

The above picture clearly shows that there has been an error, what the error is, and an error code. The response only has three attributes, but they’re all helpful.
Phase 2: The Client Is Implemented and Being Used by End Users
During this stage in the life cycle of the client, we’re not expecting any more developer errors, such as using the wrong endpoint, missing parameters, and the like, but there could still be problems caused by the data generated by the user.
Client applications that request some kind of input from the user are always subject to errors on the user’s part, and even though there are always ways to validate that input before it reaches the API layer, it’s not safe to assume all clients will do that. So the safest bet for any API designer and developer is to assume there is no validation done by the client, and anything that could go wrong with the data will go wrong. This is also a safe
assumption to make from a security point of view, so it’s providing a minor security improvement as a side effect. With that mindset, the API implemented should be rock-solid and able to handle any type of errors in the input data.
Security
Securing our API is a very important step in the development process, and it should not be ignored unless what we’re building is small enough and has no sensitive data to merit the effort. There are two big security issues to deal with when designing an API:
• Authentication: Who’s going to access the API?
• Authorization: What will they be able to access once logged in?
Authentication deals with letting valid users access the features provided by the API. Authorization deals with handling what those authenticated users can actually do inside the system
But always keep the followings in mind when developing APIs;
• RESTful systems are meant to be stateless: Remember that REST defines the server as stateless, which means that storing the user data in session after the initial login is not a good idea (if we want to stay within the guidelines provided by REST, that is).
• Remember to use HTTPS: On RESTful systems based on HTTP, HTTPS should be used to assure encryption of the channel, making it harder to capture and read data traffic (man-in-the-middle attack).
There are some widely used authentication schemes out there meant to provide different levels of security when signing users into a system. Some of the most commonly known are Basic Auth with TSL, Digest Auth, OAuth 1.0a, and OAuth 2.0.
Scalability
Scalability is usually an underestimated aspect of API design, mainly because it’s quite difficult to fully understand and predict the reach one API will have before it launches. It might be easier to estimate this if the team has previous experience with similar projects (e.g., Google has probably gotten quite good at calculating their scalability for new APIs before launch day), but if it’s their first one, then it might not be
as easy.
A good API should be able to scale—that means it should be able to handle as much traffic as it gets without compromising its performance. But it also means it should not spend resources if they’re not needed. This is not only a reflection of the hardware on which the API resides (although that is an important aspect) but also a reflection of the underlying architecture of that API.
Over the years, the classic monolithic design in software architecture has been migrating into a fully distributed one, so splitting the API into different modules that interact with each other makes sense. This provides the flexibility needed to not only scale up or down the resources that are affected but to also provide fault tolerance and help developers maintain cleaner codebases among other advantages.
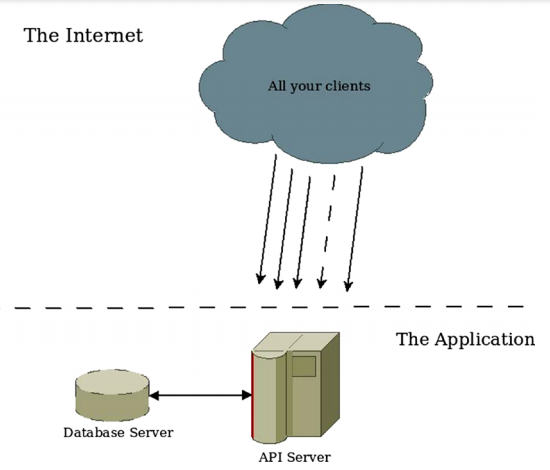
The following image shows a standard monolithic design, having our app inside one server, living like one single entity.
In the below image we see a distributed design. If compared with the above image, we can see where the advantages come from (better resource usage, fault tolerance, easier to scale up or down, etc.).
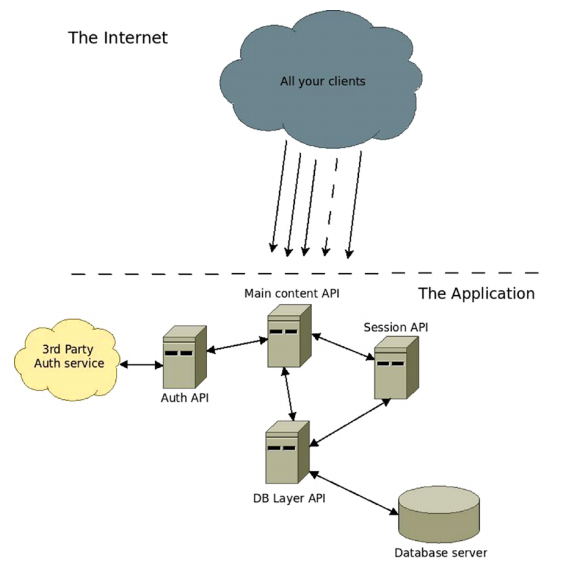
Achieving a distributed architecture to ensure scalability using REST is quite simple. Fielding’s paper proposes a distributed system based on a client–server scheme. So splitting the entire system into a set of smaller APIs and having them talk to each other when required will ensure the advantages mentioned earlier.
Up-to-Date Documentation
No matter how unique our endpoints are, we still need to have documentation explaining everything that our API does. Whether optional parameters or the mechanics of an access point, the documentation is fundamental to having a good DX, which translates into more users.
A good API requires more than just a few lines explaining how to use an access point (there is nothing worse than discovering that we need an access point but it has no documentation at all) but needs a full list of parameters and explanatory examples. Some providers give developers a simple web interface to try their API without having to write any code. This is particularly useful for newcomers. There are some online services that allow API developers to upload their documentation, as well as those that provide the web UI to test the API; for example, Ex: Swagger, OpenAPI, Postman.
Multiple SDK / Libraries
If we expect our API to be massively used across different technologies and platforms, it might be a good idea to develop and provide support for libraries and SDKs that can be used with our system. By doing so, we provide developers with the means to consume our services, so all they have to do is use these services to create their client apps. Essentially, we’re shaving off potential weeks or months (depending on the size of our system) of development time.
Another benefit is that most developers will inherently trust our libraries over others that do the same because we’re the owner of the service those libraries are consuming. Finally, consider open-sourcing the code of our libraries. These days, the open-source community is thriving. Developers will undoubtedly help maintain and improve our libraries if they’re of use to them.
Thanks for reading and see you all in the next blog post.